Lecture 10 - Tuning (continued)
# More Tuning
# Index Tuning
Topics
- Types of queries
- Index structure
- Clustered vs. non clustered indexes
- Covering/composite indexes
- Indexes on small tables
- Recommendations
# Types of Queries
- Point Query
| |
- Multipoint Query (Index tuning is especially usefull to reduce disk accesses on non clusteres indexes)
| |
- Range Query
| |
- Prefix Match Query
| |
- Extremal Query (in a B+ Tree you would only need to follow the rightmost path)
| |
- Ordering Query
| |
- Grouping Query (using HASH if no index is available)
| |
- Join Query (Prevent nested loops)
| |
# Index Structure
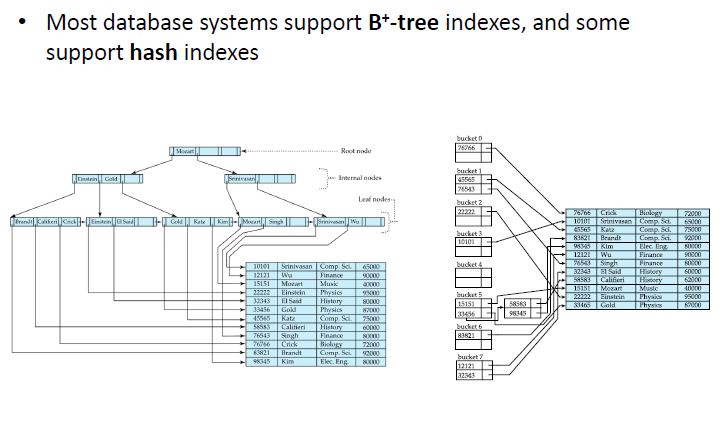
# B+ -Tree
- Always start from root (Good general purpose index structure)
- Useful for range queries and extremal queries, where hash indexes are not
- SQL Server mostly uses this
- Minimize height by having more children per node
- Length of search key influences fanout (number of children per node)
- Choose a small key when creating an index
- If the key is large, it may be possible to use key compression
- store only part of the key to distinguish between neighbors
- e.g. store ’ Smi ‘, Smo ‘, Smy ’ instead of ‘Smith’, ‘Smoot’, '
- Log search
# Hash
- Straight to row
- Faster than B+ -trees for point queries and multipoint queries
- UNLESS overflow buckets
- Must be reorganized if there is a significant amount of overflow
- Size of hash structure is not related to length of search key
- hash function is applied on key to locate bucket with pointers
# Clustered vs. non-clustered indexes
Clustered index
- Co-locates records whose values are near to one another
- For B+-trees, two values are near if they are close in sort order
- Good for point, multipoint, partial match, general join queries
- For hash indexes, two values are near only if they are identical
- Good for point, multipoint, equijoin queries
- For B+-trees, two values are near if they are close in sort order
- Non-clustered index
- A non-clustered index is independent of the table organization
- There may be several non-clustered indexes per table
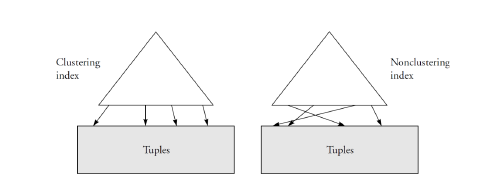 Clustered indexes can be dense or sparse
Clustered indexes can be dense or sparse
- Dense index
- pointers are associated to records; one index entry per record
- Sparse index
- pointers are associated to pages; one index entry per page
- any values 𝑣1≤𝑣<𝑣2can be found on the same page as 𝑣1
- Non clustered indexes must be dense
- cannot be sparse, since values 𝑣1≤𝑣<𝑣2can be anywhere
# Benefits of a Clustered Index
- A sparse clustered index stores fewer pointers than a dense index (Less height in B+-Tree)
- A clustered index is good for multipoint queries
- A clustered index can improve equality joins
# Evaluation of Clustered Indexes with Insertions
- Insertions cause page splits and extra I/O for each query
- Maintenance consists in rebuilding or reorganizing the index
- With maintenance, performance is constant
- Without maintenance, performance degrades
# Redundant Tables
- There can be only one clustered index per table
- Question: Wouldn’t it be nice to have multiple clustered indexes?
- Answer:
- Replicate table to use a clustered index on a different attribute
- Works well only if low insertion/update rate
# Benefits of Non-clustered Indexes
A non-clustered index is good if the query retrieves few records compared to the number of pages in the table
- Always useful for point queries
- Useful for multipoint queries if table contains many distinct values
- In an experiment was observed that an index is good if query selectivity < 15% of records At some point, a table scan becomes better than using a non-clusters index
# Covering
A non-clustered index can eliminate the need to access the underlying table through covering
- Example:
- with a composite index on ( A , B , C ) or
- with a covering index on A that includes B and C
- the query below can be answered based on the index alone
| |
- It might be worth creating multiple indexes to increase the likelihood that the optimizer finds a covering index
| |
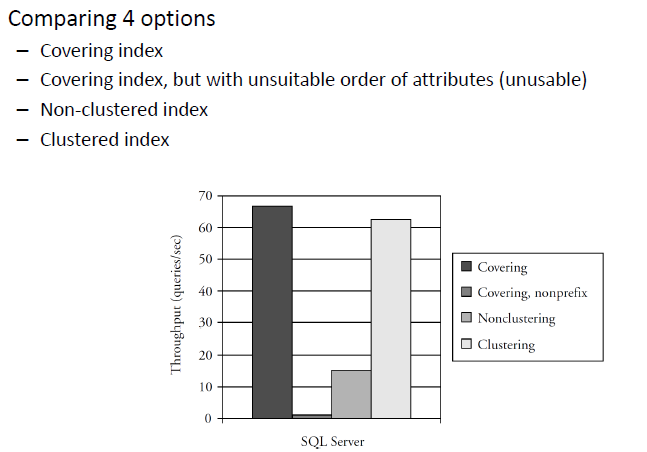
# Covering/composite indexes
A non-clustered index can eliminate the need to access the underlying table through covering or composite index
| |
- A good covering index would be on ( dept , name )
- Index on ( name , dept ) would be useless
Drawbacks
- Tends to have a large size
- Update to an attribute causes index to be modified
# Composite Search Keys
To retrieve records with age =30 AND salary =4000
- Index on ( age , salary ) is better than index on age or index on salary
- Index could be clustered or non-clustered If condition is 20< age <30 AND salary <5000
- Clustered index on ( age , salary ) or salary, age ) is best If condition is age =30 AND salary <5000
- Clustered index on ( age , salary ) is better than salary, age
# Indexes on small tables
- Indexes reduce the scope of locks
- Indexes might not be justified when thinking on queries, but on updates or concurrent transation it might bring isolation to those transactions
# Notes
- Use a hash index for equality queries
- Use a B+ tree if equality and non equality queries may be used
- Use clustered indexes if:
- queries need all (or most) fields in records,
- records are too large for a composite index,
- and multiple records are returned per query
- If possible, use a covering index for critical queries
- Do not use index if the time lost inserting and updating overwhelms time saved when querying
# Optimizing workloads
- Modern database systems: automated tuning wizards
- Provide a workload as input
- Two step approach
- best index
- best subset of index
- Consider both the benefits and the overhead
# Lock and log tuning
# Log tuning
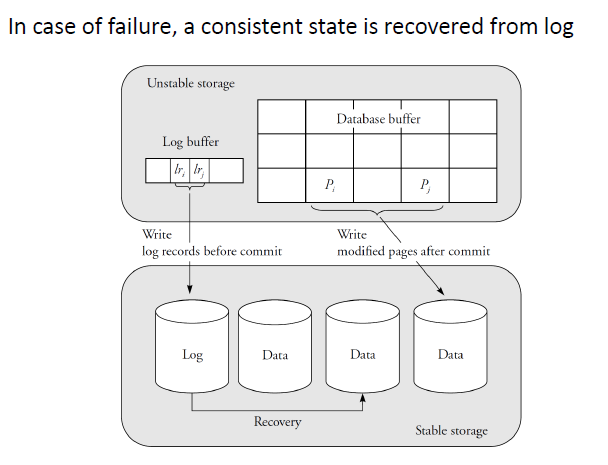
- The data disk and log disk should be separate
Topics
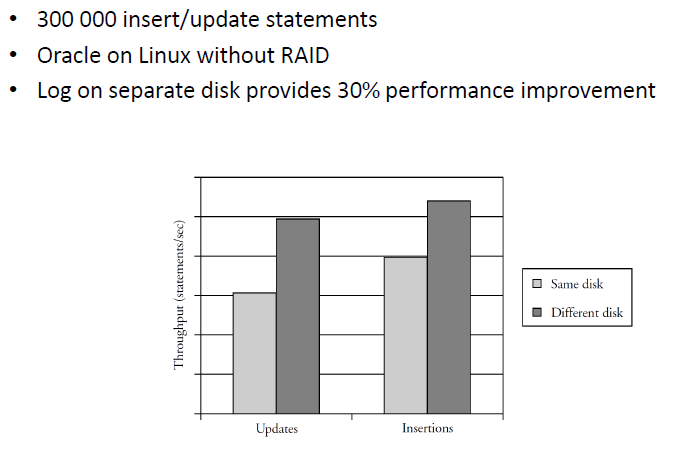
- Put the log on a separate disk
- Delay output to database disks
- Database dumps and checkpoints
- From batch to minibatch transactions
Tuning the recovery system
# Lock tuning
# Trade-off between correctness and performance
- Concurrency Control Goals
- Correctness goals
- Serializability: each transaction appears to execute in isolation
- Performance goals
- Reduce blocking
- One transaction waits for another to release its locks
- Avoid deadlocks
- Transactions are waiting for each other to release their locks
- Reduce blocking
# Ideal Transaction
- Acquires few locks and favors S locks over X locks
- Acquires locks with fine granularity
- Holds locks for a short time
# Eliminate unnecessary locking
Locking is not necessary when:
- Only one transaction runs at a time
- e.g. when loading the database
- All transactions are read only
- e.g. decision support queries on archival database
PROJECT RELEVANT Use available options to suppress locking
- Choose the appropriate isolation level
- Disable lock escalation (FEW LOCKS GENERATE FULL LOCK OF HIGHER OBJECT)
- when many row or page locks are converted to a table lock
- Use table hints such as WITH (NOLOCK)
# Sacrificing Isolation for Performance

# Transaction Chopping
- Rule of thumb
- Suppose T accesses data X and Y , but other transactions access X or Y and nothing else
- Then T can be divided into two transactions, one accessing X and another accessing Y
- Caution
- Adding a new transaction to a set of existing transactions may invalidate previous choppings
![]()
Trade-off The consistency of X+Y IS NOT GUARANTEED (create money or make money disappear) BUT X>=0
# Why
- Long transactions
- accessing almost all pages of a table
- should use table locks mostly to avoid deadlocks
- Short transactions
- accessing only a few records of a table
- should use record locks to enhance concurrency
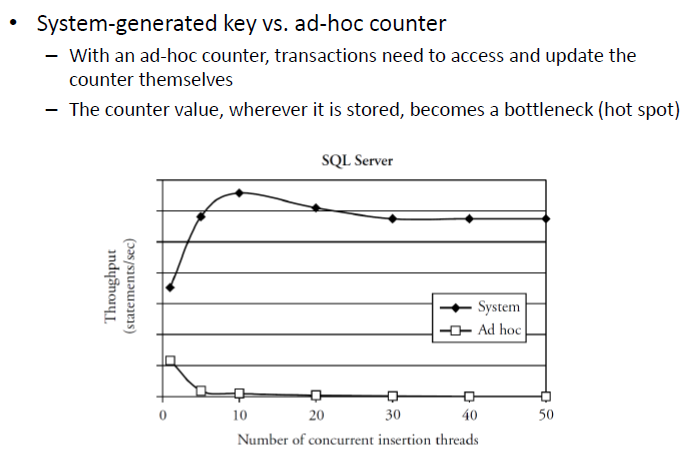
# Hot Spots
- Data item accessed by many transactions and updated by some
- e.g. max id in a table to insert a value
- Each update transaction must complete before other transactions can obtain a lock on the item (bottleneck)
- Techniques to circumvent:
- Access the item as late as possible in the transaction, to minimize the time that the transaction holds the lock on item
- Use special database management facilities; e.g. use auto increment for sequential key generation, instead of counter